今天我們就來使用Web Scraper練習爬取<ol>和<ul>兩種標籤吧~
本次練習網址為:https://fchart.github.io/test/ex3_01.html
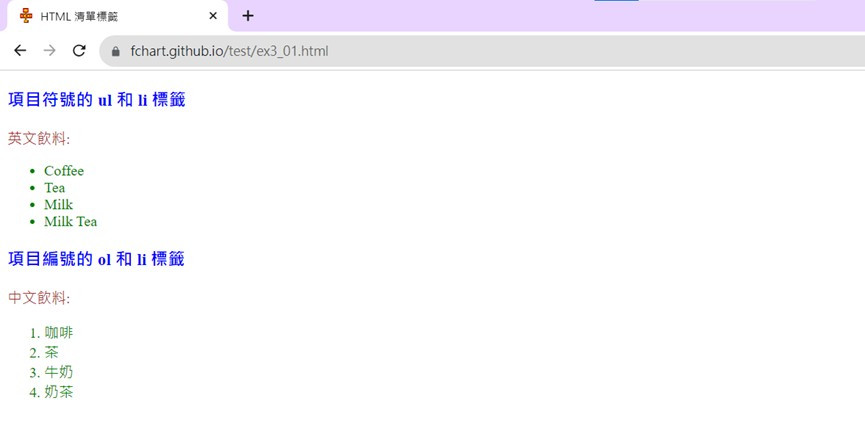
按F12或是Ctrl+Shfit+I開啟開發人員工具,停駐視窗選擇在下方;
選擇元素(Elements)標籤,可以看到<ul>和<ol>兩種標籤。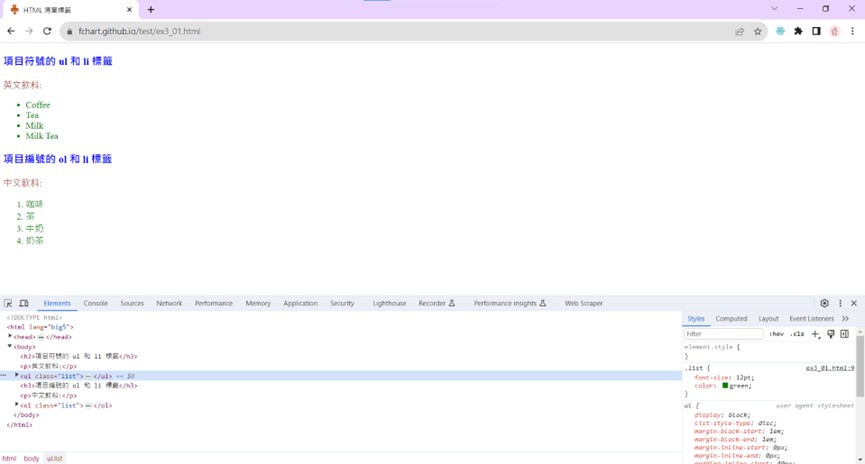
在Sitemap name輸入名稱,Strat URL欄輸入起始URL網址後按Create Sitemap新增網站地圖。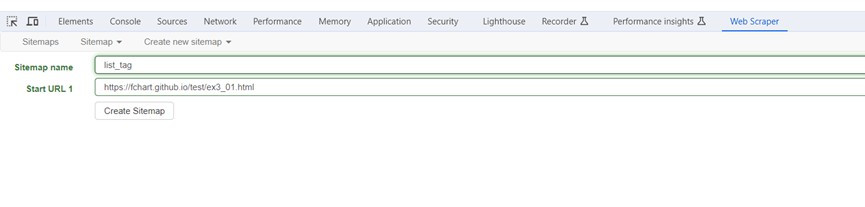
1.在下方Add new Selector紐新增目前 _root節點下的CSS選擇器節點。
2.在Id欄未輸入名稱list_tag,Type欄選Text,因為有多筆HTML清單標籤,勾選Multiple後,按Select紐。
3.在網頁移動游標,點選第一個<ul>標籤的HTML元素,可以看到CSS選擇器是ul。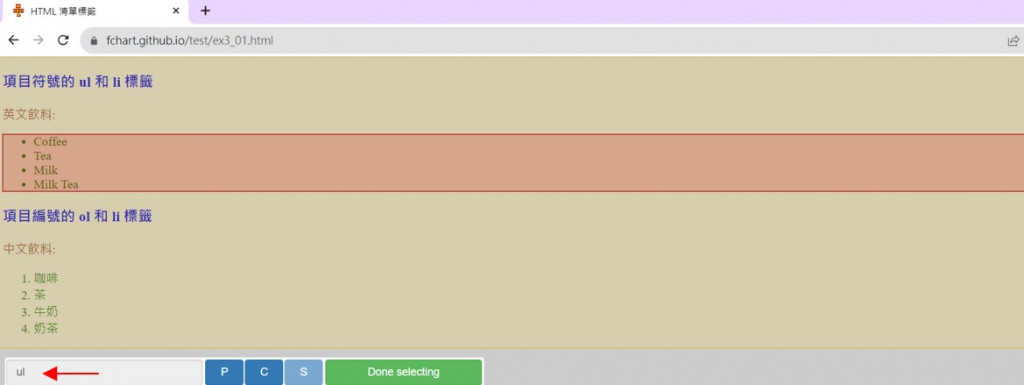
4.配合Shift鍵選取多個元素,即可點選第二個<ol>標籤,CSS選擇器是ul,ol(逗號分隔多個型態選擇器,表示同時選擇多種HTML標籤)按Done selecting紐。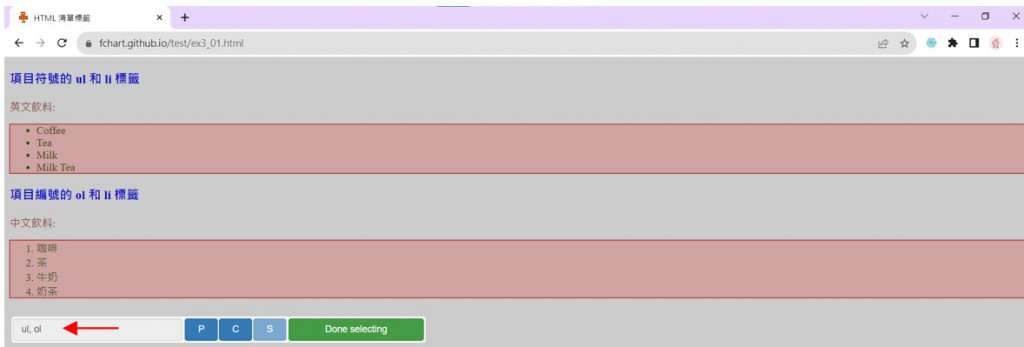
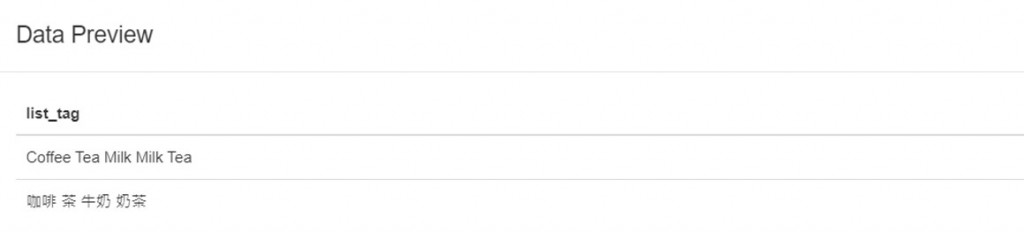
5.可在下方欄未填入CSS選擇器ul,ol,按Element preview和 Data preview紐預覽選擇的HTML元素。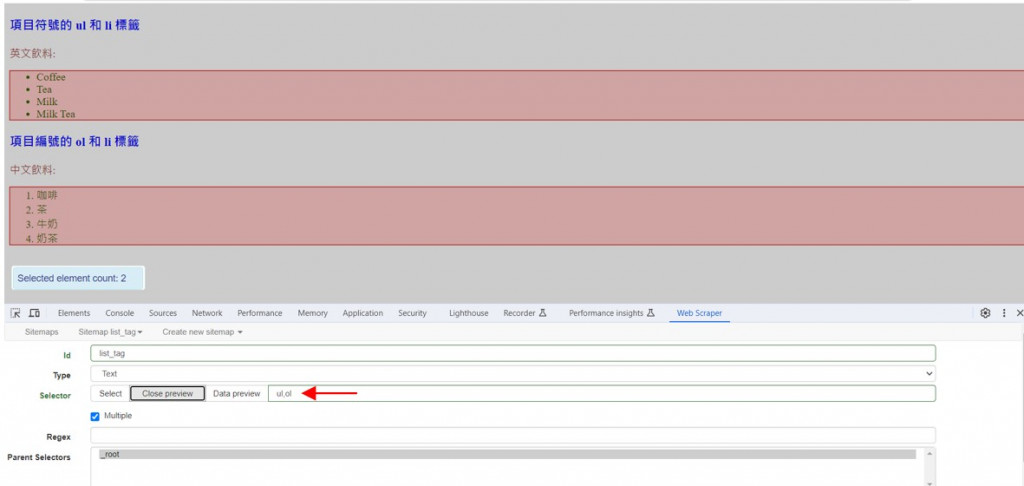
6.點選Save selector儲存選擇器節點,可以在_root跟節點下新增list_tag的選擇器節點,Multiple是yes多筆。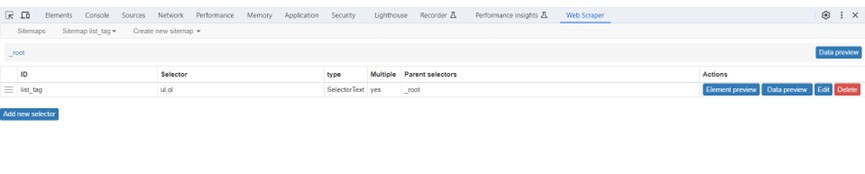
7.執行Sitemaplist_tag>Selector graph命令,一開始只有_root節點,點擊即可顯示下一層的CSS選擇器list_tag。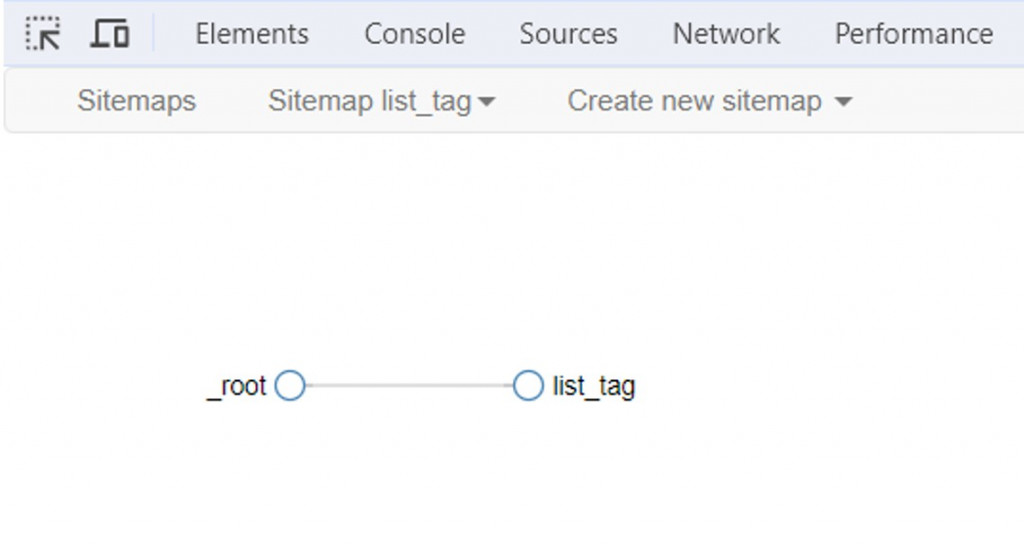
點選Sitemap title_tag → Scrape 命令執行網路爬蟲,輸入送出HTTP請求的間隔時間和載入網頁的延遲時間,預設值是2000毫秒(2秒),點選Start scraping爬取資料。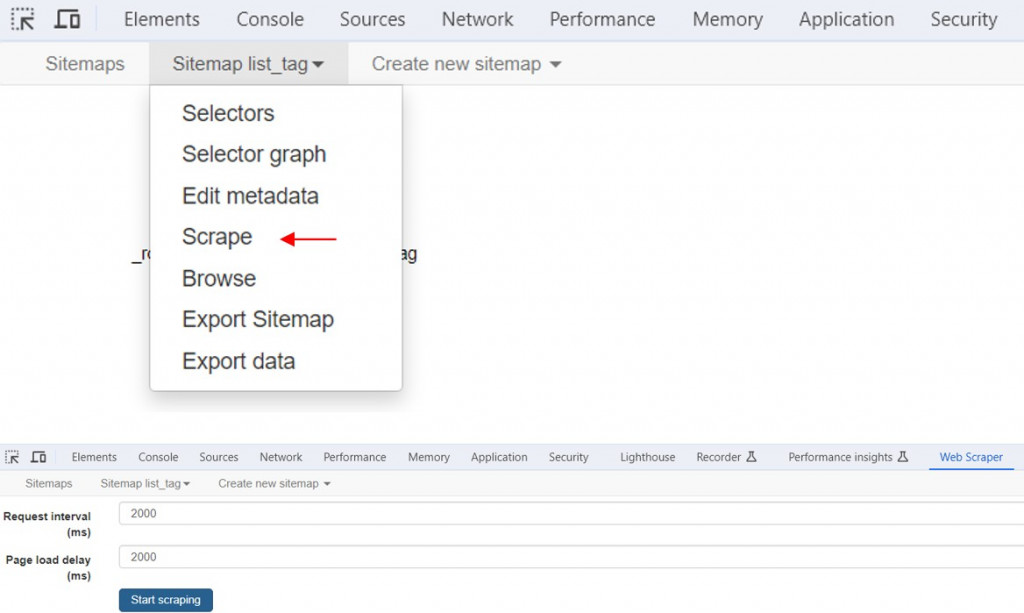
爬完之後,點選refresh重新載入資料。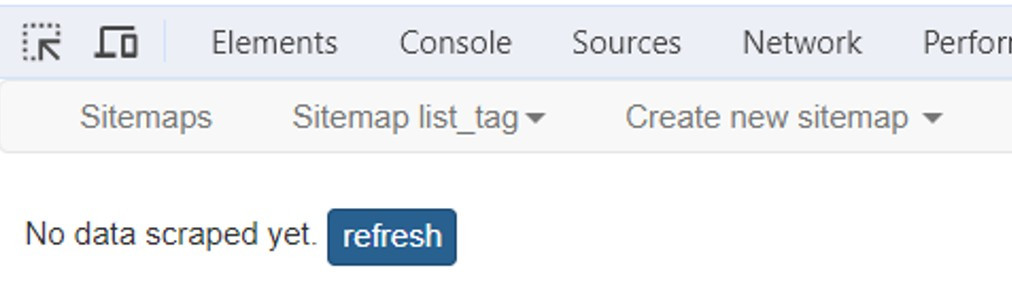
可以看到擷取完的資料有兩個清單<li>的內容,這是用空白字元分隔的項目資料。
接著我們就來匯出爬取後的資料,將其轉為CSV檔案!
點選Sitemap title_tag → Export data → Download as .CSV,匯出爬取資料成為CSV檔案。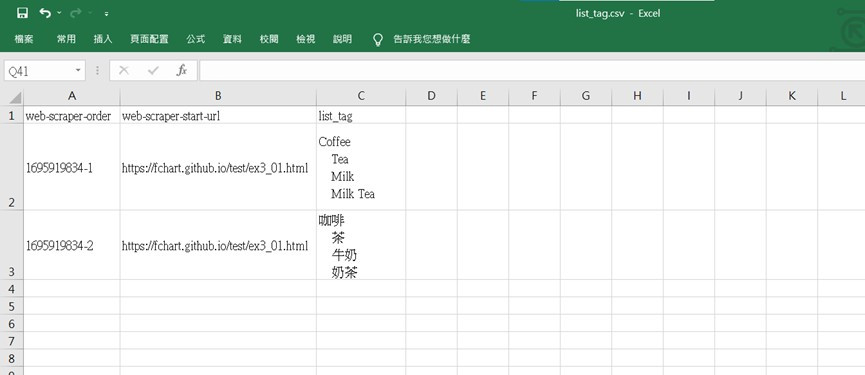
這樣子就完成啦!
今天的分享就先到這邊啦!我們明天見~ 
參考書籍資料:文科生也可以輕鬆學習網路爬蟲
資料爬取練習來源同書籍

